


| Call-site class | ||
| Function class | Non-tail call | Tail call |
| ESCAPING | Standard call | Standard tail-call |
| KNOWN | Known call | Known tail-call |
| TAIL | n.a. | |
| LABEL | n.a. | Goto |
val f : (t1, ..., tn) -> (s1, ..., sm)In the code below, we use f to refer to the callee's closure. A function closure is a two-word record consisting of a code pointer (refered to by cp) and an environment pointer (refered to by ep). We use sp to refer to the stack pointer, fp to refer to the frame pointer, exh to refer to the current exception handler continuation, arg[i] to refer to the ith argument, and res[i] to refer to the ith result.
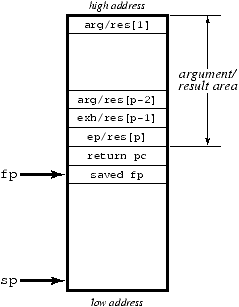
Figure 10.1: The standard stack-frame layout
cp = f[0] ep = f[1] *--sp = arg[1] ... *--sp = arg[n] *--sp = exh *--sp = ep sp -= k call *cp res[1] = sp[m-1] ... res[m] = sp[0] sp += mWhen n+2 ³ m, let k = n+2-m
cp = f[0] ep = f[1] *--sp = arg[1] ... *--sp = arg[n] *--sp = exh *--sp = ep call *cp res[1] = sp[n+2] ... res[m] = sp[k] sp += n+2Note that when f is a known function, we can call directly to f's label and we do not need cp.
cp = f[0] ep = f[1] fp[n+3] = arg[1] ... fp[4] = arg[n] fp[2] = ep sp = fp fp = *sp++ jump *cpWhen l > n, let k = l - n.
cp = f[0] ep = f[1] fp[l+3] = arg[1] ... fp[k+4] = arg[n] fp[k+3] = exh fp[k+2] = ep fp[k+1] = fp[1] sp = fp fp = *sp sp += (k+1) jump *cp
basePtr = allocPtrMASK; taskPtr = basePtr->taskPtr; taskPtr->allocPtr = allocPtr; ... call C function ... allocPtr = taskPtr->allocPtr;The wrapper code for the Moby callback gets the allocation pointer from the task structure on entry and saves it on exit (see Section 10.1.9 below).
fun inc (r : Ref(Int)) -> () { *r := *r + 1 }is compiled into the following instruction sequence on the IA32:
inc: pushl movl movl 16(incl (leave ret $12By applying the leaf-procedure optimization, we can reduce it to the following:
inc: movl 12(incl (ret $12This optimization works by first rewriting the entry and exit code sequences and then rewriting each block to replace frame-pointer based addressing with stack-pointer based addressing. The one subtlety is that MLRISC considers any basic block that has non-local control flow (i.e., because of a throw) to be an exit block. Thus, the exit sequence rewriting has to recognize such cases and ignore them. The leaf-procedure optimization can be disabled with the --no-leaf-opt command-line option.